Artificial Intelligence

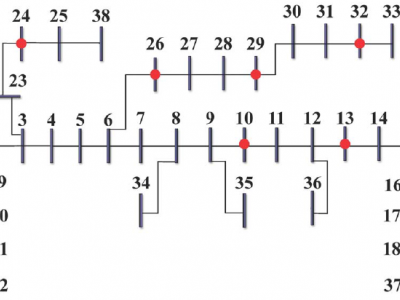
This dataset is the supporting simulated data for the paper titled "Hidden Border Tunnels: Research on Excavation Monitoring and Excavation Path Prediction." These data are generated through physical simulations and are used to validate the effectiveness of the algorithms proposed in the paper. The dataset includes the coordinates of simulated vibration events, as well as the prediction results of excavation events by various machine learning models, such as RNN, LSTM, GRU, Transformer, CNN_Transformer, and LSTMTransformer.
- Categories:
 19 Views
19 ViewsThis dataset is the supporting simulated data for the paper titled "Hidden Border Tunnels: Research on Excavation Monitoring and Excavation Path Prediction." These data are generated through physical simulations and are used to validate the effectiveness of the algorithms proposed in the paper. The dataset includes the coordinates of simulated vibration events, as well as the prediction results of excavation events by various machine learning models, such as RNN, LSTM, GRU, Transformer, CNN_Transformer, and LSTMTransformer.
- Categories:
1 Views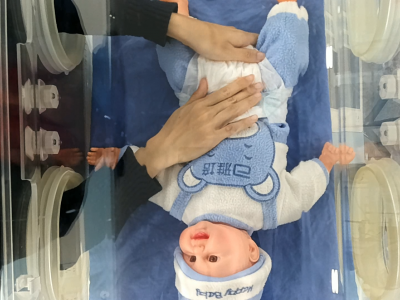
NICU-Care is a high-quality video dataset designed to support visual recognition tasks in Neonatal Intensive Care Unit (NICU) scenarios, including nursing action recognition, object detection, and semantic segmentation. It was constructed in a standardized simulated NICU environment, capturing multi-view RGB videos of professional nurses performing six types of routine caregiving procedures on simulated infants. The dataset provides fine-grained temporal annotations and pixel-level segmentation masks for key objects like nurse hands, medical tools, and infant body parts.
- Categories:
48 Views
The dataset includes BIM-IoT integration data such as Revit model, images, and IoT time-series data. The abstract is as follows: Automatic indoor environmental quality (IEQ) monitoring plays a pivotal role in the management of green building operations. Traditional monitoring methods that integrate Building Information Modeling (BIM) and the Internet of Things (IoT) are unable to perform automatic detection. This study addresses the limitation by introducing a BIM-AIoT based ‘LabMonitor’ approach for real-time IEQ monitoring and prediction.
- Categories:
22 Views
Furthermore, we introduce A Multi-Modal Continuous Emotion Annotation Dataset for VR Action Games (MMEAD-VRAG), the first multi-modal time-series dataset incorporating both physiological and behavioral signals in VR action gaming scenarios. A comparative analysis with existing state-of-the-art datasets reveals that MMEAD-VRAG exhibits fewer limitations in terms of data collection methodology, dataset scale, and participant diversity.
- Categories:
5 Views
This dataset contains simulated records for 3,000 students, generated for the purpose of evaluating fairness in predicted grading models. The dataset includes decile rankings based on historical performance, predicted grades, and demographic attributes such as socioeconomic status, school type, gender, and ethnicity. The data was created using controlled randomization techniques and includes noise to reflect real-world prediction uncertainty. While entirely synthetic, the dataset is designed to mimic key structural patterns relevant to algorithmic fairness and educational inequality.
- Categories:
5 Views
This dataset contains simulated records for 3,000 students, generated for the purpose of evaluating fairness in predicted grading models. The dataset includes decile rankings based on historical performance, predicted grades, and demographic attributes such as socioeconomic status, school type, gender, and ethnicity. The data was created using controlled randomization techniques and includes noise to reflect real-world prediction uncertainty. While entirely synthetic, the dataset is designed to mimic key structural patterns relevant to algorithmic fairness and educational inequality.
- Categories:
7 Views
This dataset consists of images with two types of artificially added noise, intended for evaluating the robustness of machine learning models against noise perturbations. The first type of noise introduces randomly generated pixel values ranging from 0 to 255 at random positions in the image. The second type of noise adds binary noise by setting pixels at random locations to either 0 or 255. The dataset includes images with varying amounts of noisy pixels, allowing for detailed analysis under different noise intensities.
- Categories:
23 Views
This paper explores public perceptions surrounding the use of Artificial Intelligence (AI) in cultural and media production across the Arab region. Based on a comprehensive questionnaire distributed among 2000 participants, the study investigates attitudes toward AI-driven content, ethical concerns, cultural identity threats, educational impacts, and legal responsibilities.
- Categories:
54 Views